過去十年,儘管機器學習已經在影象識別、決策制定、NLP 和影象合成等領域取得很多成功,但卻在自動駕駛技術領域沒有太多進展。這是哪些原因造成的呢?近日,Lyft 旗下 Level 5 自動
2021-08-24 03:04:10
過去十年,儘管機器學習已經在影象識別、決策制定、NLP 和影象合成等領域取得很多成功,但卻在自動駕駛技術領域沒有太多進展。這是哪些原因造成的呢?近日,Lyft 旗下 Level 5 自動駕駛部門的研究者對這一問題進行了深入的探討。他們提出了自動駕駛領域的「Autonomy 2.0」概念:一種機器學習優先的自動駕駛方法。


一是基於規則的規劃器和模擬器無法有效地建模駕駛行為的複雜度和多樣性,需要針對不同的地理區域進行重新調整,它們基本上沒有從深度學習技術的進展中獲得增益;
二是由於基於規則的模擬器在功效上受限,因此評估主要通過路測完成,這無疑延遲了開發週期;
三是 SDV 路測的成本高昂,且擴展性差。

將堆棧表示為端到端可微網路;
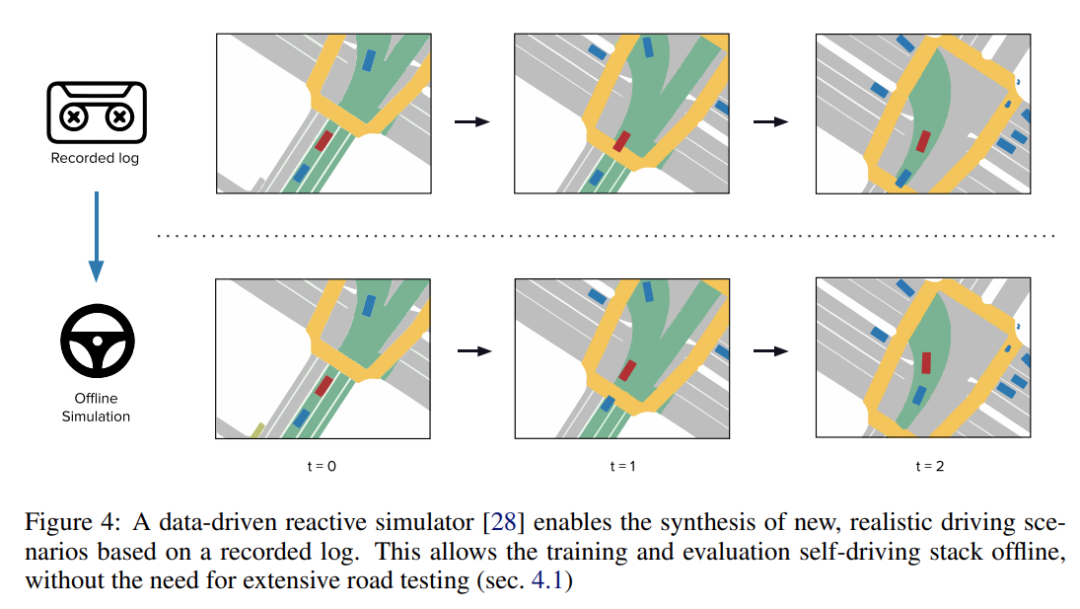
在閉環中利用機器學習的模擬器進行離線驗證;
收集訓練這些模擬器需要大量人類駕駛資料。
適用於任務的模擬狀態表徵;
能夠以高保真度和強大的反應能力合成多樣化和逼真的駕駛場景;
應用於新的場景和地域時,效能隨著資料量的增加而提升。

每個元件,包括規劃,都需要可訓練且端到端的可微分;
可使用人工演示進行訓練;
效能與訓練資料量成正比。

足夠的規模和多樣性以包括罕見事件的長尾;
足夠的感測器保真度,即用於收集資料的感測器需要足夠準確才能有效地訓練規劃器和模擬器;
足夠便宜,可以以這種規模和保真度收集。

模擬和規劃的恰當狀態表示是什麼?我們應如何衡量場景概率?
我們應如何檢測異常值(outlier)以及從未見過的情況(case)?
與使用搜索進行的實時推理相比,通過人類演示進行離線訓練的極限在哪裡?
我們需要在模擬上投入多少?又應如何衡量離線模擬本身的效能?
我們在訓練高效能規劃和模擬元件上需要多少資料?在大規模資料收集時又應該使用什麼感測器呢?
相關文章
過去十年,儘管機器學習已經在影象識別、決策制定、NLP 和影象合成等領域取得很多成功,但卻在自動駕駛技術領域沒有太多進展。這是哪些原因造成的呢?近日,Lyft 旗下 Level 5 自動
2021-08-24 03:04:10

博雯 發自 凹非寺量子位 報道 | 公眾號 QbitAI因為嚴重痛經入院,在醫囑下注射阿片類藥物(Opioid)以緩解痛苦。結果入院四天後,就突然被AI告知:你將不會再接受任何阿片類藥物。然
2021-08-24 03:04:04

出品|開源中國文|御阪弟弟郵件列表顯示,英特爾為其 DG2 顯示卡提交了啟用裝置記憶體支援的補丁。DG2 顯示卡現在的代號為 「Alchemist」,是英特爾推出的全新高效能顯示卡品牌
2021-08-24 03:03:51

今日,俄羅斯一遊戲支付公司用AI裁員150人的新聞登上知乎熱搜,引發關注和熱議,這是什麼情況呢?截圖自知乎熱榜,侵刪據悉,該遊戲支付公司將公司增長指標定在增長40%,然後圍繞這一增長
2021-08-24 03:03:46

說軟體測試有可能被替代或者被淘汰的人,他一定不懂軟體測試首先,我們來想想什麼行業容易被替代和被淘汰?最容易被替代的是工作流程很固化的崗位。比如:早期的紡織工人,很固化的在
2021-08-24 03:02:30

蘋果釋出會開始錄製據之前訊息來看,蘋果將會在下個月也就是九月份舉辦隆重的秋季釋出會,釋出全新的 iPhone13 系列產品和全新的系統版本。由於新冠疫情的影響,蘋果本次也依然不
2021-08-24 03:02:24